short-essay on illusions
September 09, 2025
If there is a severe deficit of language,
there will be severe deficit of thought.
Noam Chomsky
Rewinding to September 2024, OpenAI released their o1-preview model, the first AI explicitly designed to “think” before responding using something called chain-of-thought reasoning, a technique previously introduced by a Google Research team in late 2022. This opened the doors for the rest of AI companies and by 2025 everyone was looking up for presenting their own thinking models:
- DeepSeek-R1 (January 2025) showed everyone how it could build reasoning capabilities using just reinforcement learning
- Anthropic’s Claude 3.7 Sonnet (February 2025) introduced the first hybrid reasoning architecture, allowing users to choose between the classic or reasoning model
These became known as Large Reasonning Models (LRMs)—AI models designed to show their step-by-step thinking process before returning a quick answer.
This rapid progress hit a major roadblock when Apple—who had been harshly criticized for their weak efforts in the AI research—published a paper in June 2025 with a controversial and provocative title: “The Illusion of Thinking”. This paper questioned the very foundation of LRMs stating that:
despite their sophisticated self-reflection mechanisms learned through reinforcement learning, these models fail to develop generalizable problem-solving capabilities for planning tasks, with performance collapsing to zero beyond a certain complexity.
The argument started an uncomfortable discussion and unveiled various viewpoints over Apple’s statement, even making Anthropic publish a critical response only days after in their own paper The illusion of the illusion of thinking.
The Illusion
With the intent of having a deep understanding of the models’ reasoning capabilities, Apple created a series of, as described by them, innovative experiments that aimed at replacing the traditional math tests, which could usually be contaminated by training data—information used for training the AI models—and designed a set of puzzles that provided a “controlled environment” over the tests. These puzzles, such as the Hanói Tower or River Crossing, let the research team set precisely the desired difficulty and observe not only if the models could reach the solution, but the “thinking process” developed in between.
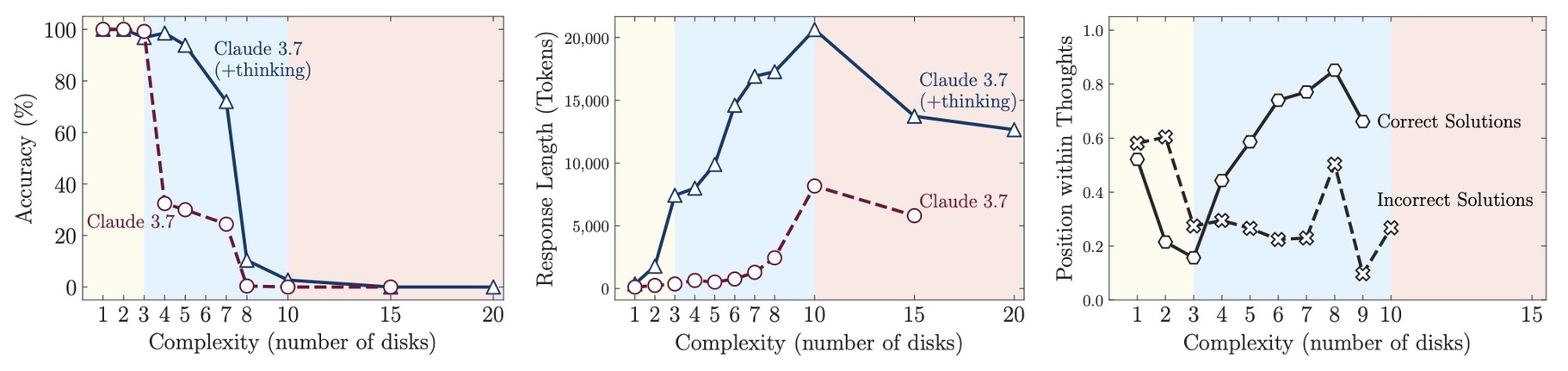
Experiments results revealed a complete performance collapse in all the reasoning models after reaching a certain difficulty. It also identified three different “performance regimens”:
- Simple tasks: Regular LLMs actually outperformed their “thinking” counterparts
- Medium complexity: Thinking models showed some advantage
- High complexity: Both types failed completely
Findings also inlcuded an overthinking phenomenon, where LRMs would often identify the correct solution early, then waste compute exploring wrong alternatives; counterintuitively, when approaching the highest complexity, models tended to stop thinking despite having resources lelft.
The Illusion of the Illusion
Just days after Apple’s paper dropped, Anthropic published their rebuttal comments, challenging Apple’s conclusions on three principal grounds:
- It’s not reasoning failure, it’s a word count problem
Anthropic argued that the observed “collapse” primarily reflected token limit constraints—a count limit models have for processing or generating at once—rather than reasoning failures. - Unsolvable Problems
They also identified a critical flaw in the River Crossing experiment: some instances where having 6 or more actors using a boat with a capacity of 3, where mathematically impossible to solve. - Different Evaluations = Different Results
The most compelling counterargument: when Anthropic changed how they evaluated the models, performance dramatically improved.
Instead of asking for exhaustive step-by-step solutions, they asked models to generate algorithmic approaches. Suddenly, models achieved high accuracy on Tower of Hanoi problems that Apple had marked as complete failures—using 12 times less computational capacity.
Is thinking really an illusion?
These results settled and reinforced the main question of both studies: Are models actually capable of reasoning, or are they just becoming better at pattern recognition? However, the controversy revealed a more fundamental issue about how we evaluate AI reasoning capabilities. The dispute between Apple and Anthropic highlighted the challenge of distinguishing between genuine reasoning failures and experimental artifacts—a critical consideration for future AI research and development.
My aim with this, as I decided to call it, short essay was to walk through the recent events and big ideas concerning the question of machine thought. As for my own take, I feel we’re still some years away from a true thinking system, even though the latest progress has been a huge step in that pursuit. I also believe a crucial next step is to create better ways of measuring a model’s “reasoning.” Apple set a clear direction here, but they may have been a little biased against their competition. So, while we’re definitely paving the way for what will become AGI, my answer right now is no—I don’t think these models can truly reason… yet.